Codepoint: U+0EA5 "LAO LETTER LO LOOT"
Block: U+0E80..0EFF "Lao"
The Lao script (Akson Lao) is a sister script of the Thai script; both derive from the Sukhothai script of the thirteenth century CE. As such, they have many similarities. For instance, both Lao and Thai consonants are given individual names. Here are the 27 Lao consonants with their typical names:
- ກ = chicken (ໄກ່)
- ຂ = egg (ໄຂ່)
- ຄ = water buffalo (ຄວາຍ)
- ງ = ox (ງົວ)
- ຈ = glass (ຈອກ)
- ສ = tiger (ເສືອ)
- ຊ = elephant (ຊ້າງ)
- ຍ = mosquito (ຍຸງ)
- ດ = child (ເດັກ)
- ຕ = eye (ຕາ)
- ຖ = bag (ຖົງ)
- ທ = flag (ທຸງ)
- ນ = bird (ນົກ)
- ບ = goat (ແບ້)
- ປ = fish (ປາ)
- ຜ = bee (ເຜິ້ງ)
- ຝ = rain (ຝົນ)
- ພ = mountain (ພູ)
- ຟ = fire (ໄຟ)
- ມ = cat (ແມວ)
- ຢ = medicine (ຢາ)
- ຣ = car (ຣົຖ)
- ລ = monkey (ລີງ)
- ວ = fan (ວີ)
- ຫ = goose (ຫ່ານ)
- ອ = bowl (ອື່ງ)
- ຮ = house (ເຮືອນ)
Each consonant's name begins with that consonant in a similar fashion to English alphabet mnemonics such a "A is for apple, B is for banana, etc.", known as acrophony:
 |
| [source] |
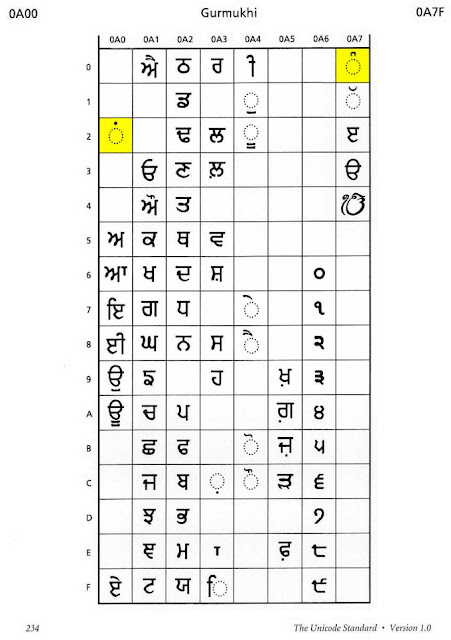
Alas, the mapping of these consonants to the appropriate "column" of the Unicode Lao block is complicated by two factors:
- The Unicode encoding is based loosely on Thai Industrial Standard 620-2533 and has holes where unused characters are omitted.
- The names of four of the consonants were incorrect when they were added to Unicode 1.0.
These complications are discussed in Andrew West's N3137 notes:
The Unicode code charts note that the Lao block is "Based on TIS 620-2529". This statement is misleading as TIS 620-2529 is a Thai standard for representing the Thai script in an 8-bit code, and does not define names or code points for the Lao script. The Unicode Lao block is based on a mapping of Lao characters to the equivalent Thai characters in TIS 620, but is not actually based on this standard.
And:
The Unicode names for Lao consonants are based on the syllabic pronunciation of the character (i.e. consonant plus inherent vowel). All consonants belong to one of three tone classes: high, mid and low. Where two letters are only distinguished phonetically by their tone class, the modifiers SUNG "high" and TAM "low" are used to indicate the tone class of the letter (e.g. U+0E82 "LAO LETTER KHO SUNG" and U+0E84 "LAO LETTER KHO TAM"). However, the Unicode names for two of the consonants have the wrong tone class applied to them:
U+0E9D "LAO LETTER FO TAM" is a high tone class letter, and should have been named "LAO LETTER FO SUNG"
U+0E9F "LAO LETTER FO SUNG" is a low tone class letter, and should have been named "LAO LETTER FO TAM"
Whilst the Unicode names for 25 of the 27 consonants use this naming scheme, the names of two of the consonants use mnemonic names (presumably because they share the same vowel and tone class, and so could not otherwise be differentiated). Mnemonic names are how the consonants are normally identified in the Lao language, although there is no official list of standard mnemonic names for consonants, and different sources may use different mnemonic names for some letters.
The two letters whose Unicode names are based on mnemonic names are:
U+0EA3 "LAO LETTER LO LING"
U+0EA5 "LAO LETTER LO LOOT"
The mnemonic names for these two letters are the wrong way round. U+0EA5 is the normal letter [l] and is universally identified by the mnemonic name lo ling "lo as in ling [monkey]". On the other hand, U+0EA3 is a letter that is used to represent [r] in foreign words; however this letter has been officially deprecated by the Lao government since 1975, and is no longer in common use. The name element LO LOOT applied to U+0EA5 would seem to represent the mnemonic ro rot, "rot" meaning automobile, that should be applied to U+0EA3.
So U+0EA3 should be named "LAO LETTER RO ROT" (car) and U+0EA5 should be named "LAO LETTER LO LING" (monkey).
It is interesting that the Unicode standard has effectively "nailed down" the names of the consonants even though Andrew West says there is no official standard.
It has always troubled me that English does not have a satisfactory mechanism for naming its letters. These are the names typically used in British English:
- a
- bee
- cee
- dee
- e
- eff
- gee
- aitch
- i
- jay
- kay
- el
- em
- en
- o
- pee
- cue
- ar
- ess
- tee
- u
- vee
- double-u
- ex
- wye
- zed
If we ignore "double-u" (which we've met before), the obvious elephant in the room is "cue" for "Q". Not only is it not acrophonic (only 15 of the 26 truly are), "Q" doesn't appear anywhere in its name.












{kind=link}