When the Universe web page first loads into a browser, about 100MB of data are pulled over the network in over 250 HTTP requests. This includes 77 web fonts (6MB), 161 glyph image sheets (77MB) and the Unicode Character Database, UCD, as a tab-separated value file (28MB).
It can take three or four minutes the first time around with a slow network connection, but all these resources are usually cached by the browser, so subsequent page loads perform very little actual data transfer. However, decoding the UCD is another matter.
Even the subset of the UCD data we're actually interested in takes up a quarter of a gigabyte when expressed as JSON. So caching the raw JSON file is problematic. I elected to transfer the data as sequential key-value deltas in TSV format. This reduces the size down to under 30MB and only 6.5MB when compressed "on the wire". It is also relatively quick to reconstitute the full UCD object hierarchy in JavaScript: it takes about seven seconds on my machine.
Here are the lines describing codepoint U+0040 ("@"):
na<tab>COMMERCIAL AT
lb<tab>ALSTerm<tab>NTerm<tab>NSB<tab>XX0040<tab>= at sign
The first five lines (in "<key><tab><value>" form) list only the differences in UCD properties (keyed by short property aliases) compared to the preceding codepoint (i.e. U+003F "?").
The next line (in "<hex>" form) creates a new codepoint record for "U+0040".
The final line (in "<tab><extra>" form) adds an extra line of narrative to the preceding record. In this case, it refers to a NamesList.txt alias.
The ucd.14.0.0.tsv file is constructed using a NodeJS script from the following sources:
- ucd.all.flat.xml (194MB) from https://www.unicode.org/Public/UCD/latest/ucdxml/ucd.all.flat.zip
- https://www.unicode.org/Public/UCD/latest/ucd/NamesList.html (1.6MB)
- https://www.unicode.org/iso15924/iso15924.txt (13KB)
It is read and reconstituted by the "LoadDatabaseFileAsync()" function of universe.js. Notice that the final action of that function is to store the data in an IndexedDB database. This allows the JavaScript to test for the existence of that data in subsequent page reloads, obviating the need to fetch and decode each time. This saves several seconds each time. See "IndexedDatabaseGet()" and "IndexedDatabasePut()" in universe.js.
The downside of using this client-side caching is that it takes up 260MB of disk space:
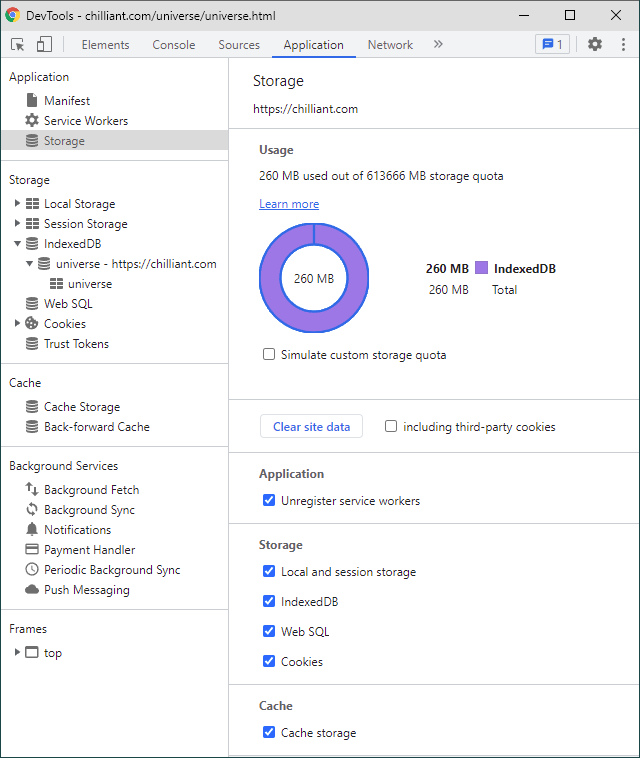
We rely on the browser (Chrome, in this case) to manage the IndexedDB storage correctly, but even if the cache is purged, we fall back over to parsing the TSV again.

No comments:
Post a Comment